ReAct 框架与 AI Agent:当 AI 学会自己思考和行动
先抛个观点:如果你的 AI Agent 还需要在提示词里用 ReAct 框架,那要么说明你用的是没有 Agent 能力的模型(比如 GPT-4o、Gemini 2.5 Pro),要么就是方法用错了。
为什么这么说?因为具备 Agent 能力的先进模型(例如 Anthropic 的 Claude 4 系列,甚至包括更早的 Claude 3.7 和 OpenAI 的 GPT-5),已经通过训练把 ReAct 的本领“内化”进去了。换句话说,只要提供正确的工具接口和描述,这些模型自己就会规划步骤、调用工具来完成任务,不需要我们再手把手用 ReAct 提示去教它们该怎么做。
那么,什么是 ReAct? 它和 Agent 能力又有什么关系?下面我将结合通俗的例子,聊聊 ReAct 提示框架以及新一代 AI Agent 模型如何通过训练掌握了这一套本领。
什么是 ReAct?
ReAct 是 “Reasoning and Acting”(推理与行动)的缩写。它是一种提示词设计框架,最初由 Yao 等人在2023年提出。ReAct 的核心思想是:让大型语言模型不再仅仅凭已有知识直接生成最终答案,而是像人一样,一边思考,一边采取行动,主动去获取答案需要的新信息。
简单来说,ReAct 就像在 AI 的大脑里植入了一个 “思考-行动-观察”的循环 机制。每当模型收到一个问题,它不会立刻给出答案,而是按照以下步骤循环运作:
• 思考(Thought):模型首先分析问题,规划解决问题的步骤,就像自言自语地拟定方案。例如它可能心想:“嗯,这问题我需要先去搜索一下相关资料。”
• 行动(Action):接着,模型决定并执行一个具体的动作。这个动作通常是使用某个外部工具,如调用搜索引擎、计算器、查数据库等。
• 观察(Observation):当行动完成后,模型会得到该动作的结果反馈。例如,搜索引擎返回了一段资料,或计算器给出了计算结果。
• 重复:模型将新获取的观察结果纳入考虑,更新自己的思考,然后进入下一轮
Thought→Action→Observation循环。它会不断这样迭代,直到确信自己收集到了足够的信息来回答原始问题为止。
举个简单的例子,加深一下理解:
如果你问 AI:“苹果公司昨天的收盘价是多少?”
• 思考:模型的内心独白也许是:“用户在问苹果公司股票昨天的收盘价,我需要调用金融数据工具来查一下这个信息。”
• 行动:模型决定调用一个金融 API,于是发送请求查询股票代码 “AAPL” 昨天的收盘价。
• 观察:API 工具返回了结果,例如:「AAPL 昨日收盘价:175.04 美元」。
• 思考:模型得到观察结果后再次思考:“我已经拿到准确的股价,可以组织答案了。”
• 回答:最后,模型给出回答:“苹果公司昨天的收盘价是 175.04 美元。”
可以看到,使用 ReAct 框架时,AI 模型并非一下子吐出答案,而是走了一系列思考→行动→观察→再思考的步骤,类似人在解决问题时的逻辑。每一步思考都会基于目前掌握的信息决定下一步要采取的行动,直到问题解决。
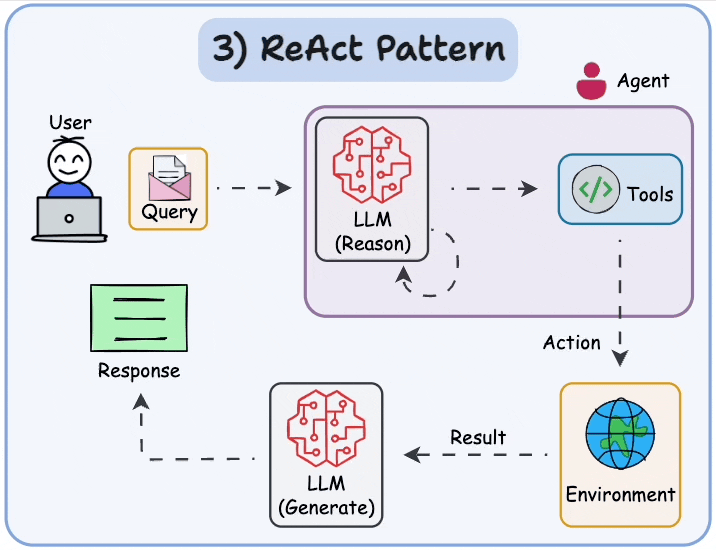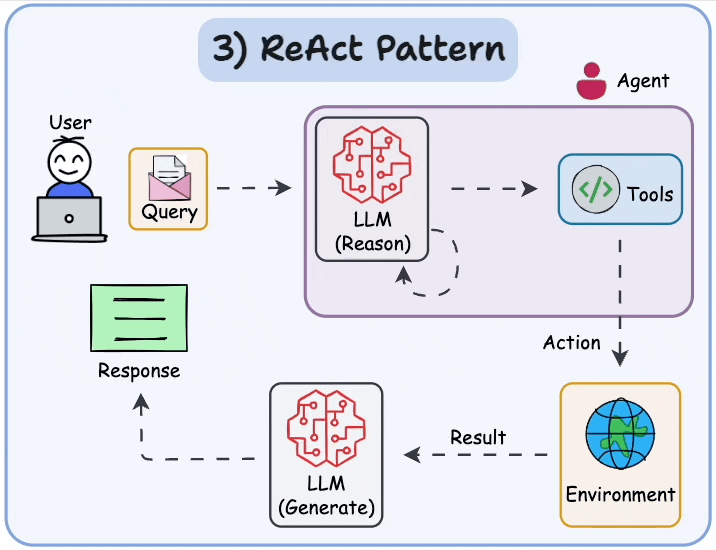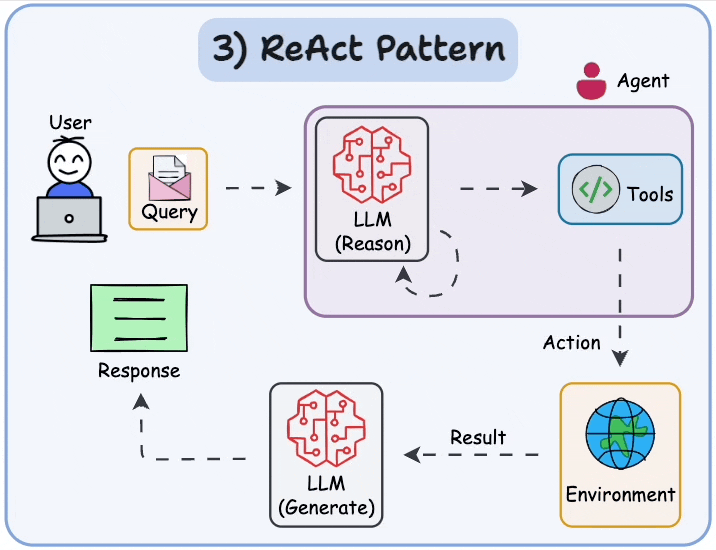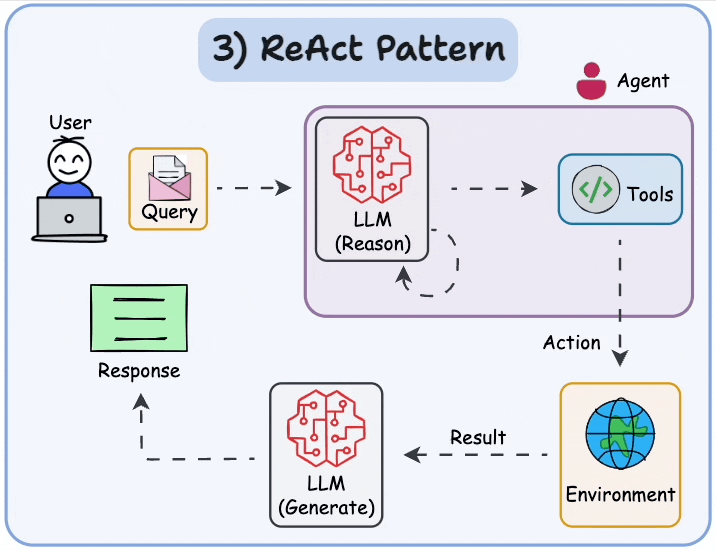
图源:Implementing ReAct Agentic Pattern From Scratch https://www.dailydoseofds.com/ai-agents-crash-course-part-10-with-implementation/
“思考→行动→观察” 循环示意图展示了 ReAct 框架下 AI Agent 的工作流程:模型先思考任务如何拆解,然后执行行动(调用工具获取所需信息),接着观察工具返回的结果,并将新信息纳入下一步思考,如此反复,直到完成目标。这个过程让AI能够像人一样一边查资料一边求解,而不是凭记忆硬答,在复杂任务上显得更聪明更可靠。*
Agent 能力模型已经内化了 ReAct
理解了 ReAct,我们再来看什么是“Agent能力的模型”。简单来说,有 Agent 能力的模型指的是那些能够自主规划、多步推理并使用工具完成复杂任务的 AI。这类模型经过特殊训练,具备以下能力:
• 任务规划:能够自行把复杂问题分解成更小的步骤,规划解决方案的流程;
• 工具使用:能够根据需求调用外部工具(如搜索引擎、数据库、代码执行器等)来获取信息或执行操作;
• 自我判断:能够根据工具反馈判断任务是否已经完成,是否需要进一步行动。
换句话说,Agent 型模型就像一个训练有素的智能体,一旦给它赋予工具和目标,它自己就会想办法解决问题。
那么,有了 Agent 能力的模型为何不需要我们提供 ReAct 提示词了呢? 因为它们已经在训练中学会了这种“思考-行动”模式,把 ReAct 框架融入到了自身能力里。
下面通过一个调试代码的例子,对比一下没有 Agent 能力的旧模型与具备 Agent 能力的新模型在解决复杂任务时的区别:
• 使用传统模型 (无 Agent 能力):
假设我们让一个没有 Agent 能力的模型(比如老版 GPT-4o)来定位并修复程序中的Bug。以前,我们必须在提示词里编写一大串 ReAct 风格的指令,指导模型先输出思考过程,然后我们用程序代码去解析模型输出的“行动”指令,再去执行对应的工具(比如检索代码库或运行测试)。执行完后,再把结果反馈给模型,让模型继续“观察”结果并思考下一步……整个流程需要我们在模型之外写代码和提示词来操控,相当繁琐。模型本身就像一个刚毕业的新手程序员,你得给他准备好详尽的操作手册(提示词),一步步教他该做什么、怎么做。他只会严格按照你提供的 ReAct 模板格式来思考和行动,没有这些详细提示就不知所措。• 使用 Agent 能力模型:
现在换成一个具备 Agent 能力的模型(例如 Anthropic Claude 4 Sonnet)。你几乎不需要写什么复杂提示词框架,只要告诉它:“这里有调试代码的工具,可用。请帮我找到并修复这个Bug。” 模型就会自行规划调试步骤:它也会先思考从何下手,可能先调用代码检索工具定位问题代码,然后运行测试工具查看输出,再根据结果调整方案……整个思考-行动循环都由模型在内部完成了。对我们开发者来说,控制逻辑简单很多,只需要一个循环检测模型的响应:如果模型回应的是要用某个工具,那就调用该工具并把结果给它;如果模型直接给出了最终答案或修复方案,那就结束。就这么一个小小的while循环,模型就能自动完成调试任务。这个模型就像一个经验丰富的工程师,不需要照本宣科——因为他已经把书本知识内化于心,遇到问题能主动想办法解决,不用你一步步教。
打个比方:以前用老模型,就仿佛你雇了个菜鸟程序员,必须给他一本详细的操作手册(ReAct 提示词),手把手指导;而现在的 Agent 模型是个资深高手,早就把那本“手册”融会贯通,丢开手册也能独立完成工作。
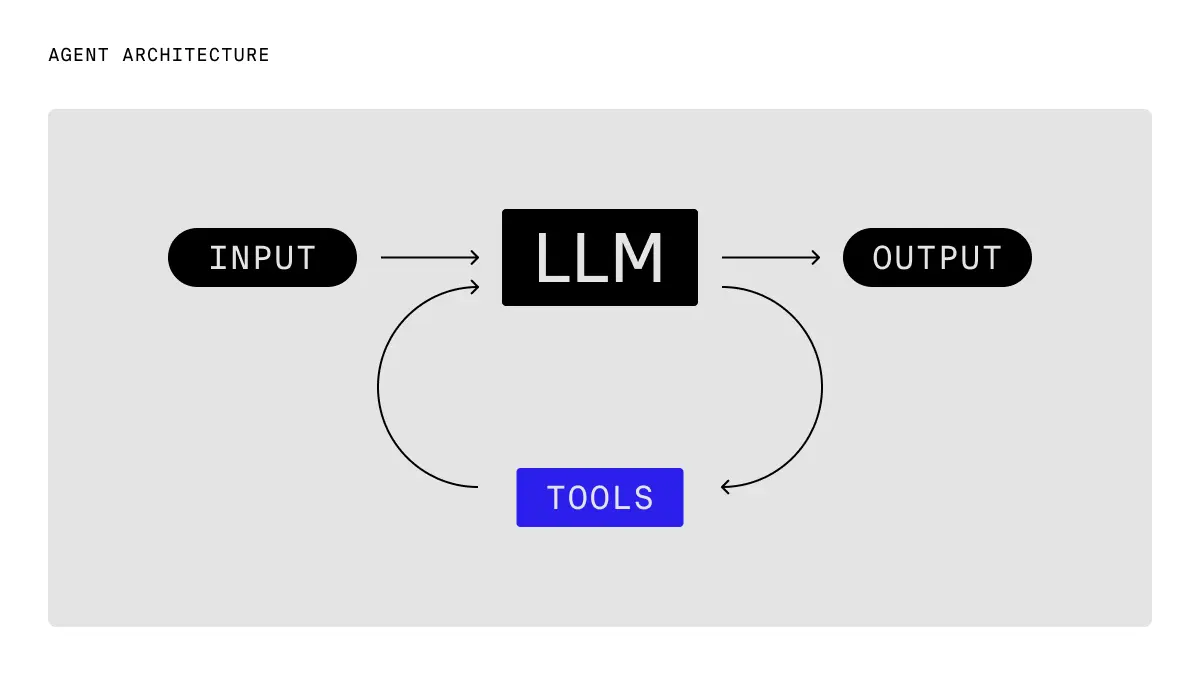
图源:The canonical agent architecture: A while loop with tools https://www.braintrust.dev/blog/agent-while-loop
现代 AI Agent 可以自主调用工具完成任务。例如,假设用户问:“纽约现在的天气怎么样?”。具备 Agent 能力的 AI 大脑中会先思考:“用户想知道实时天气,我有一个
get_weather工具可以查天气。” 随后 AI 发起行动调用天气API获取纽约当前气象数据,并观察到结果:“纽约当前多云,15°C,湿度60%。” 最后 AI 会综合这个新信息给出解答。整个过程中,我们并没有特别教它每一步该怎么做——模型自己规划了查询步骤并正确使用了工具,把问题圆满解决。这种自动规划和工具调用的能力,正是新一代 Agent 型模型的强大之处。*
常见疑问解答
问: 模型的规划能力(把问题分解的能力)算是 Agent 能力的一部分吗,还是算推理能力的一部分?针对一个复杂问题,是用一个擅长推理的模型先分析并给出计划,再交给Agent执行;还是让Agent自己基于推理去规划并执行?
答: 一般来说,推理能力是 Agent 能力的前提。没有推理,就谈不上真正的智能决策。所以一个强大的 Agent 模型,一定具备良好的推理分析能力。对于复杂问题,是否需要分解步骤、以及如何解决,取决于问题类型:如果问题本身不需要借助外部信息(比如较复杂的数学题),仅靠模型的推理就能一步到位解决,那用不着 Agent 那套工具调度。但如果问题涉及获取外部知识或多步骤操作(比如调试代码、检索特定资料等),这时候就需要 Agent 能力,让模型通过规划步骤并调用工具与外部环境交互来完成。简单总结:推理是大脑,Agent是手脚,两者缺一不可,复杂任务中往往需要大脑分析后再用手脚去干活。
问: 现在很多新模型据说内置了工具调用能力,只要提供工具列表,模型就能自主选择并使用工具。但也有人实验发现,用显式的 ReAct 提示框架(即让模型先输出思考步骤再选工具)往往效果比模型内置的工具调用还更好。这是为什么?是不是老的 ReAct 反而更有效?
答: 这个要具体情况具体分析。可以这样理解:固定流程的明确任务适合用预先设计好的“工作流”,而开放式的问题更适合让 Agent 自由探索。ReAct 相当于是我们人为设计的一套流程,如果你很清楚解决某类问题的最佳步骤是什么,那硬性按照这个步骤提示模型,可能会又快又准(毕竟你帮它规划好了)。但如果遇到开放性的问题,没有固定解法,让模型自行探索往往更通用、更省心。这时候内嵌的 Agent 规划就更有优势,因为模型可以随机应变,不受预设流程限制。所以并不存在绝对谁优谁劣,而是要看场景和模型能力。理想情况下,两者结合:明确有最佳套路的,用工作流效率更高;无法预知步骤的,让 Agent 自由发挥更合适。
问: 现在有了具备 Tool-Calling(工具调用)能力的大模型,是不是就不需要再用提示词去指导它如何使用工具了?ReAct 框架是不是仍然需要?
答: 对于有 Agent 能力的大模型来说,确实不需要再在提示里写详细的 ReAct 步骤了。模型已经通过训练学会了何时该调用工具、如何解析工具的反馈,也知道在得到答案后何时停止。这正是我们说它把 ReAct 能力“内化”了。你只需把可用的工具及其用途告诉它,模型就能自己决定下一步。就像前面说的,大学刚入门时我们需要照着教材写代码,等毕业后早已融会贯通,写代码早脱离了教材。那些新一代模型经过大量强化学习和实例训练,早就把 ReAct 那套思路学会了,不需要我们在提示词里显式教它步骤。ReAct 框架本身对于这些模型来说不再是提示词,而变成了它们思考过程的一部分。当然,如果你用的是不支持 Agent 的旧模型,那该写的提示还是得写,模型自己是不会无缘无故遵循这个流程的。
问: 一个模型只要具备调用工具的能力,是不是就算有了 Agent 能力?
答: 不完全是。会用工具只是 Agent 能力的一部分。真正强大的 Agent 还需要会自主规划任务、遇到复杂问题知道拆解步骤,并且能判断任务是否完成。有些模型具备了工具调用接口,比如可以按照预定义格式请求搜索或计算,但如果它不会自行规划多步查询的策略,不会根据工具结果调整行为,那还称不上一个成熟的 Agent。换句话说,Tool Calling ≠ Full Agent。Agent 型模型是既能决定用什么工具、何时用,又能在拿到结果后判断是否要继续,直到最终目的达成。这种自主性和决策力,才是真正的 Agent 能力所在。一个模型可能有工具插件,但若缺乏自主的规划和循环决策能力,仍需要人为一步步指引,那它充其量只是“会用工具的聊天机器人”,还称不上智能体。
最后
伴随着大模型技术的发展,我们正见证从“问答式”智能到“Agent式”智能的飞跃。ReAct 提示框架曾经是让模型迈出行动的一副“拐杖”,而如今最先进的模型已经学会了自己走路。这并不意味着 ReAct 完全过时了——在某些场景下,我们仍然会用明确的提示引导模型逐步推理。但可以预见,随着模型能力的增强,开发者将能更省心地把复杂任务交给 AI,让它自主规划解决。
对于普通技术爱好者来说,这背后的原理无非是:模型变聪明了,我们反而可以少操心了。今后,当你使用那些会自己上网查资料、会调用工具帮你完成工作的 AI 助手时,不妨记得:这是因为它们体内早已“内置”了一套 ReAct 思考与行动的本领,让 AI 更加像一个真正能干的智能体,为我们带来前所未有的便利体验。