Jeff Dean 深度访谈:一页纸备忘录促成 Gemini 的诞生,Google AI 的反击与 10,000 Token 的未来
宝玉

从 MapReduce、BigTable 到 TPU、Google Brain,再到 Gemini,Jeff Dean 参与或主导了 Google 几乎所有核心 AI 基础设施的构建。他是 Google 的第 30 号员工,现任首席科学家、Gemini 项目负责人。
在 Latent Space 播客最近一期节目中,主持人 Alessio 和 Swyx 与 Jeff Dean 进行了一个多小时的深度对话。话题跨度极大:从蒸馏技术的真实起源,到“能否让 AI 关注整个互联网”的长上下文愿景;从用皮焦耳理解为什么 GPU 需要批处理,到那份改变了 Google AI 格局的一页纸备忘录。
原始播客链接:https://www.latent.space/p/jeffdean

要点速览
- 蒸馏是桥梁,前沿大模型是蒸馏的前提。Google 每一代 Gemini 都做到了“下一代 Flash 等于或超过上一代 Pro”
- Flash 模型已进入 Gmail、YouTube、Google 搜索 AI Mode,处理量超 50 万亿 token
- 长上下文的终极目标是“回答问题时能注意到整个互联网”,但二次方注意力机制在百万 token 就到极限了,需要类似 Google 搜索的分层检索架构
- 一次矩阵乘法约 1 皮焦耳,从芯片 SRAM 搬一个参数约 1000 皮焦耳。这个 1000 倍的差距就是批处理必须存在的物理原因
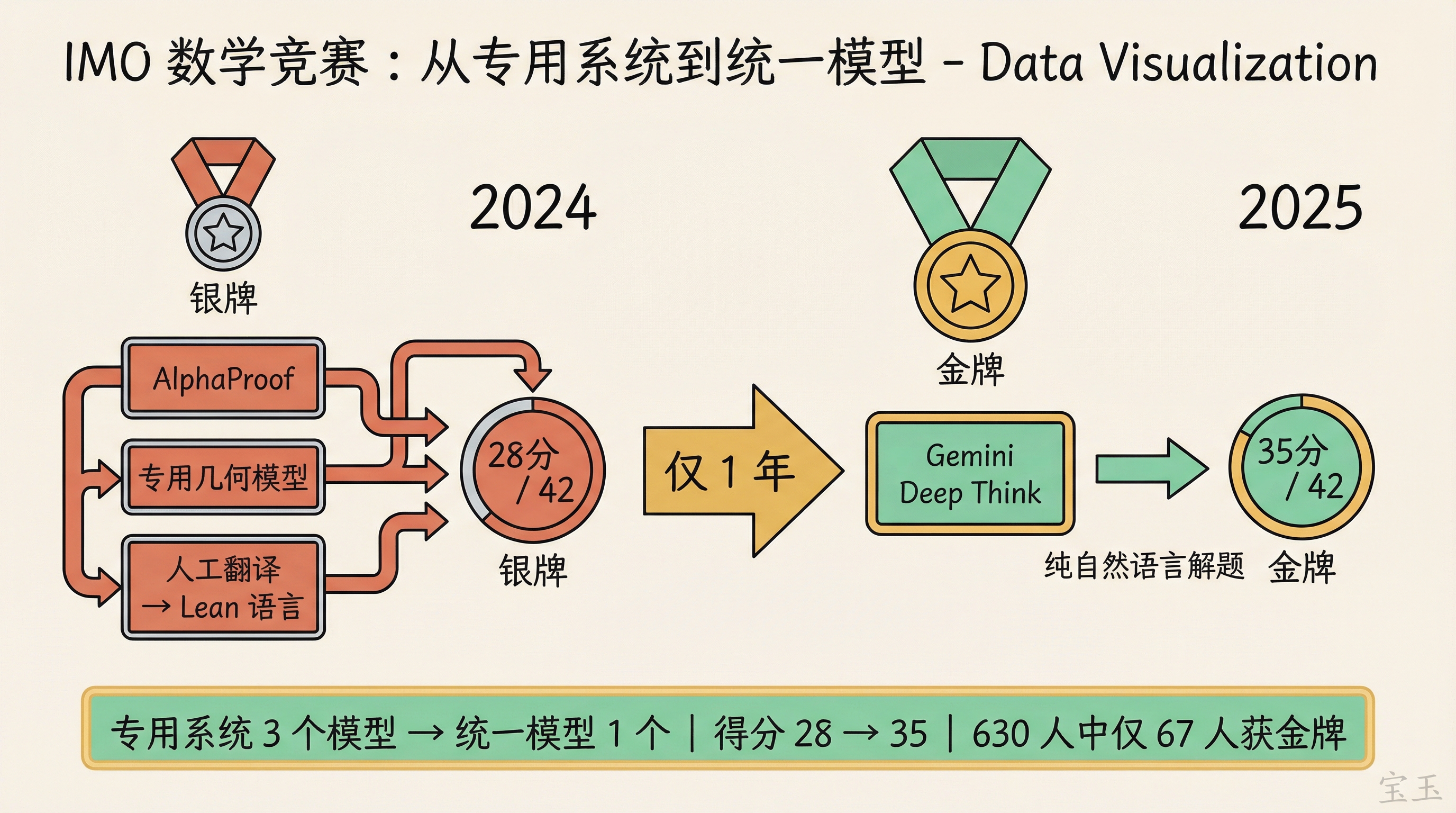
- IMO 数学竞赛:2024 年需要 AlphaProof + 专用几何模型 + 人工翻译到 Lean 语言才拿银牌(28 分),2025 年直接用 Gemini Deep Think 以自然语言拿金牌(35 分)
- Gemini 诞生于 Jeff Dean 的一页备忘录,核心论点:三路分兵做大模型是“愚蠢的”
- Jeff 预测 10,000 token/秒将成为有意义的目标,不是为了输出更多代码,而是用 9000 token 推理、输出 1000 token 精炼代码
大模型和小模型都要做
主持人 Alessio 上来就恭喜 Jeff Dean“拥有了帕累托前沿”,并追问:新实验室都在拼命推高性能上限来融资,而 Google 有几十亿用户需要服务,你们怎么在前沿能力和部署效率之间做取舍?
【注:帕累托前沿(Pareto Frontier)指在多个目标之间不可能同时改善的最优权衡边界。在 AI 模型的语境中,指在性能和成本/速度之间同时做到最优。】
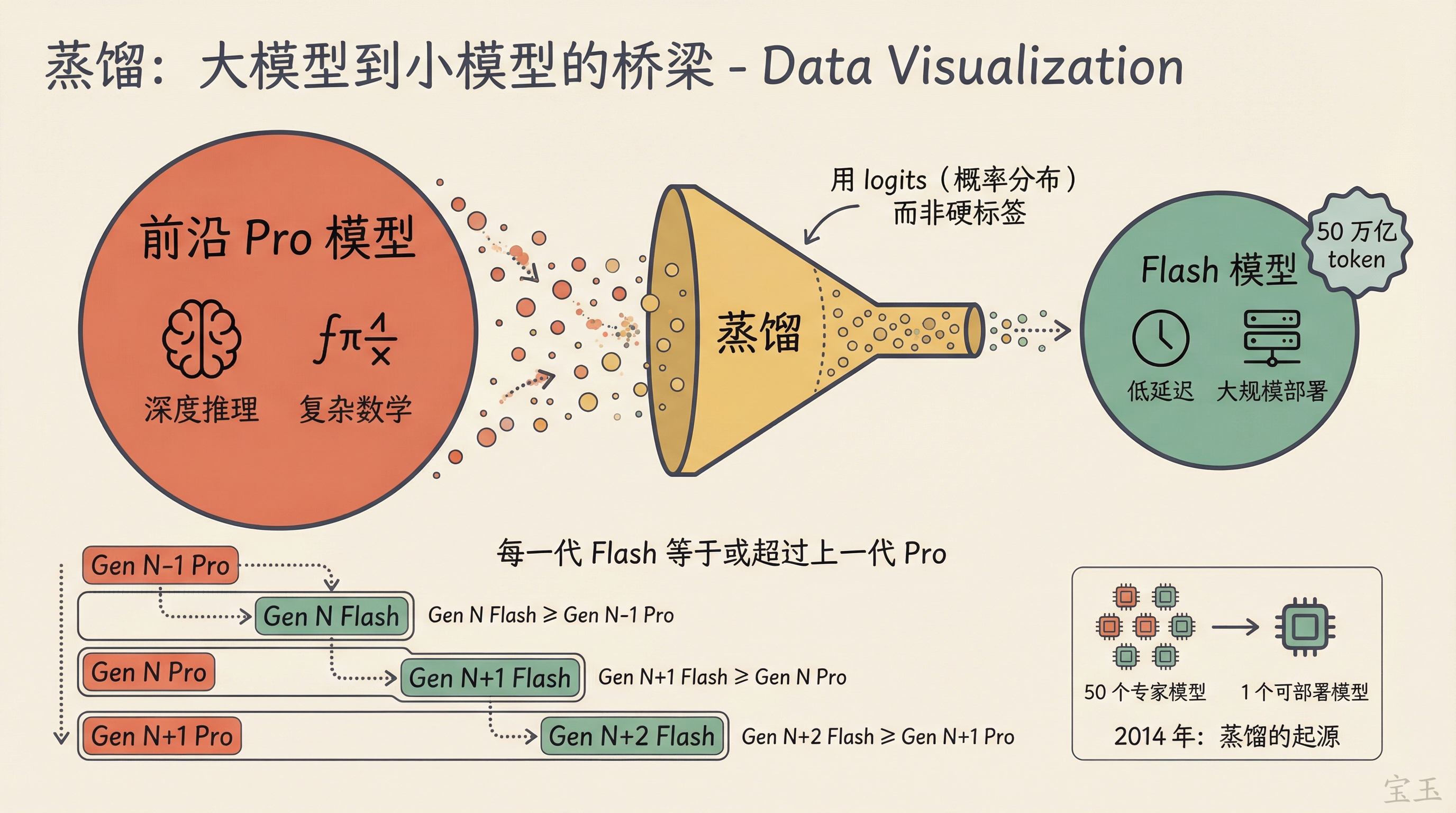
Jeff Dean 说这从来不是二选一。Google 始终维护两条线:一条是用于深度推理和复杂数学的前沿 Pro 模型,一条是低延迟、可大规模部署的 Flash 模型。蒸馏把这两条线串在一起,没有前沿大模型,就不可能蒸馏出好的小模型。
“通过蒸馏,你必须先有前沿模型,才能把它蒸馏成更小的模型。所以这不是二选一的问题。”
Google 已经连续多代 Gemini 做到了“下一代 Flash 等于或超过上一代 Pro”。
Alessio 追问:如果蒸馏总能让下一代 Flash 赶上上一代 Pro,那再过两代谁还需要 Pro?
Jeff 的回答是:这个推理的前提是用户需求不变,但实际上模型越强,人们会提出越复杂的需求。他用自己的经历举例:一年前只敢让模型做简单编程任务,现在会要求它完成复杂得多的事情。不只是编程,现在有人会问“帮我分析全球所有可再生能源部署情况”,这在一年前根本不会有人提。前沿模型的价值不仅是服务高端需求,还在于探索能力的边界,发现模型在哪里失败,从而指导下一代的改进方向。
【注:蒸馏(Distillation)是一种模型压缩技术。常规训练用硬标签("这是猫"或"不是猫"),蒸馏改用大模型的 logits,也就是模型输出的概率分布,包含了"这张图有点像猫又有点像虎"这类微妙信息,小模型能从中学到远多于硬标签的知识。】
蒸馏的真实起源:50 个专家模型的部署难题
主持人提到蒸馏论文是 2014 年的工作,问 Jeff 当初怎么想到这个方向的。
Jeff 回忆说,当时 Google 内部有一个非常大的图像数据集,大约 3 亿张图片、2 万个类别,远比 ImageNet 大得多。他们发现,给不同类别子集训练专门的“专家模型”——一个特别擅长识别哺乳动物、一个特别擅长识别室内场景——把大约 50 个专家模型组成集成,效果非常好。
但 50 个模型没法上线。蒸馏就是为了解决这个部署问题:怎么把集成的知识压缩到一个能实际部署的单一模型里。
蒸馏的核心优势是你可以用一个小得多的模型,在非常大的训练集上跑很多遍,因为你现在拿到的是大模型的 logits,而不是硬标签。这能从小模型里“哄”出它本来学不到的行为。
这和今天做 Gemini 的逻辑完全一样。只不过以前是 50 个专家模型的集成,现在是一个超大规模的单一模型蒸馏到更小的模型。
Swyx 追问了 Ultra 模型的状态:是不是 Google 藏着一个超大模型在不断蒸馏?Jeff Dean 的回答有意模糊:
“我们有很多不同类型的模型。有些是内部模型,不一定要发布或上线服务。”
言下之意:Google 内部确实有比公开版本更大的模型,但不一定都会对外发布。
Flash 已无处不在:50 万亿 token 的背后
Alessio 提到 Flash 的 token 处理量已超过 50 万亿。Jeff Dean 说这纯粹是因为 Flash 的经济性好到可以“用在所有地方”。
它现在驱动着 Gmail、YouTube,也在 Google 搜索的 AI Mode 和 AI Overviews 中使用。Swyx 听到 Flash 驱动 AI Mode 时明显惊讶,Jeff Dean 自己似乎也是在对话中才意识到这点值得提。
除了便宜,Jeff Dean 认为低延迟是 Flash 的另一个核心优势。未来的任务会比现在复杂得多,不是“帮我写个 for 循环”,而是“帮我写一个完整的软件包”。从提出需求到完成任务之间要生成大量 token,低延迟在这种场景下至关重要。
TPU 的芯片间高速互连在这里也发挥了作用,对长上下文的注意力计算和稀疏专家模型的部署都很友好。
Benchmark 的保质期
Swyx 问 Google 内部用什么 benchmark,因为外部公开的那些分数已经快刷满了。
Jeff Dean 说好的 benchmark 应该在初始阶段让模型只拿到 10-30% 的分数,然后可以推动改进到 80-90%。一旦超过 95% 就没什么价值了,因为要么能力已经达标,要么公开数据中存在泄露。
Google 内部有大量保留测试集(held-out benchmarks),确保不在训练数据中出现,覆盖了 Google 希望模型拥有但目前还不具备的能力。
他举了长上下文的例子。Needle in a Haystack(在长文本中找一根针)这个基准在 128k token 上下文已经饱和了,大多数模型都能满分。但 Google 在推 100 万甚至 200 万 token 的上下文长度,真正有用的基准应该是多针(multi-needle)或更接近真实使用场景的任务,比如“读完这些内容后回答一个综合性问题”。
“回答问题时,注意力能覆盖到整个互联网吗?”
Swyx 从 benchmark 话题自然过渡到长上下文的方向性问题。Jeff Dean 没有纠结具体方案,而是直接拉到了终极目标:
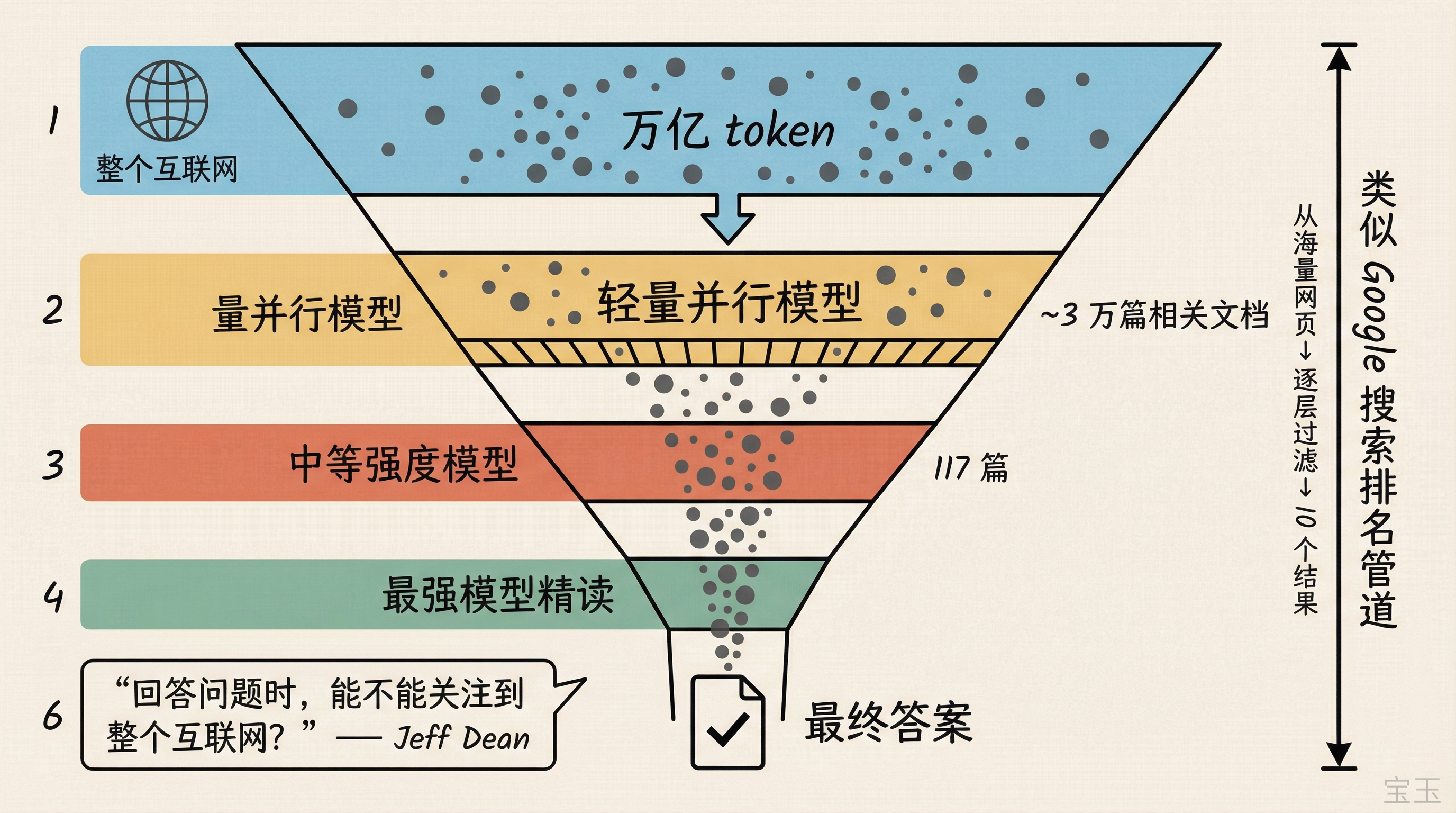
“你真正想要的是:回答问题的时候,注意力能覆盖到整个互联网吗?”
但他立刻指出这不可能靠现有方案实现。当前注意力机制是二次方复杂度,100 万 token 已经接近极限,不可能直接推到 10 亿、万亿级。
那怎么办?Jeff Dean 提出了一个分层漏斗式的架构设想:用高度并行的轻量模型从万亿 token 中筛选出大约 3 万篇相关文档,再用稍强的模型从 3 万缩小到 117 篇,最后用最强的模型精读这 117 篇来完成任务。
这个思路和 Google 搜索的排名管道异曲同工,从海量网页逐层过滤到最终的 10 个结果。只不过现在终端用户不是人类,而是另一个 AI 模型。
这个愿景延伸到个人层面:如果你授权,一个个性化的 Gemini 可以“关注”你的所有邮件、照片、文档、机票,从而提供真正个人化的帮助。
Swyx 补充说,一个人每天说 8 小时的话也就产生大约 10 万 token,完全可以装进上下文。但如果要理解视频、蛋白质等高信息密度的模态,那就是完全不同的量级了。
多模态不只是图文:从 LIDAR 到 120 人使用的语言
Swyx 问:有没有某些模态是“国王模态”,可以涵盖其他模态?
Jeff Dean 说,Gemini 从一开始就是多模态设计的,不光是文本、图像、视频、音频这些“人类模态”,还包括 Waymo 的 LIDAR 数据、机器人数据、X 光、MRI、基因组信息。他认为世界上可能有几百种有意义的数据模态,即使不在预训练中大量包含,让模型少量接触也很有用,因为这会让模型知道“这种东西存在”。
至于“国王模态”,Jeff 认为视觉和运动确实是最重要的:
“进化独立演化出眼睛 23 次,因为视觉对感知周围世界是如此有用的能力。”
他举了个例子:给模型一个 YouTube 体育集锦视频(18 个跨越 20 年的经典体育瞬间),让它做一个表格,列出每个事件的名称、日期和描述。模型能准确输出一个 18 行的结构化表格。大多数人不会把“视频转结构化表格”当成一个典型 AI 用例来想,但这恰恰说明了原生视频理解能力的价值。
Swyx 补充说 Gemini 仍然是唯一原生支持视频理解的模型。Jeff Dean 还提到一个细节:Kalamang 语全球只有约 120 人使用且没有书面文字,但把它的全部语料放进上下文,Gemini 就能学会在上下文中使用这种语言。
2001 年,Google 把整个搜索索引搬进了内存
Alessio 问到 Google 搜索如何为 AI 时代做准备。Jeff 讲了一个 Google 搜索历史上的关键转折。
2001 年左右,Google 面临两个需要同时扩展的维度:索引规模(更多网页)和流量容量(更多查询)。他们用的是分片系统,随着索引增长不断增加分片,随着流量增长不断增加每个分片的副本。
当时他们有大约 60 个分片,每个分片 20 个副本,一个数据中心里就有 1200 台带磁盘的机器。他们做了一个关键的计算:一份完整的索引,刚好能放进这 1200 台机器的内存里。
于是他们把整个索引搬进了内存。
这个变化带来的质量提升惊人。之前基于磁盘时,每一个查询词都需要在每个分片上做磁盘寻道,所以必须严格限制查询扩展:用户搜 3-4 个词,系统就只查这 3-4 个词。但索引在内存里之后,系统可以放心地扩展到 50 个相关词,加入同义词。搜“restaurant”可以同时搜“restaurants”、“cafe”、“bistro”。这是 2001 年的事,远在 LLM 之前,但核心思路已经是“从匹配词形到理解词义”。
Jeff 给出了一个通用设计原则:设计系统时,最重要的参数应该能扩展 5-10 倍,但不超过 100 倍。因为如果某个参数突然变成 100 倍,那意味着设计空间里出现了一个完全不同的最优解。就像从磁盘索引到内存索引,一旦流量大到有足够多的副本机器,内存方案就突然变得可行了。
另一个数据:Google 索引的更新频率从最初的每月一次,到后来任意页面不到 1 分钟就能更新。
【注:Google 搜索架构的多代演进从未正式发表论文。Dean 2009 年在 WSDM 会议上做过一次演讲,覆盖了 1999-2005 年间四五代架构的重新设计。】
用皮焦耳理解 AI 硬件:批处理的能量真相
Swyx 提到了 Jeff 的经典之作“Latency Numbers Every Programmer Should Know”,问如果要为 AI 时代更新这份清单,会加什么。
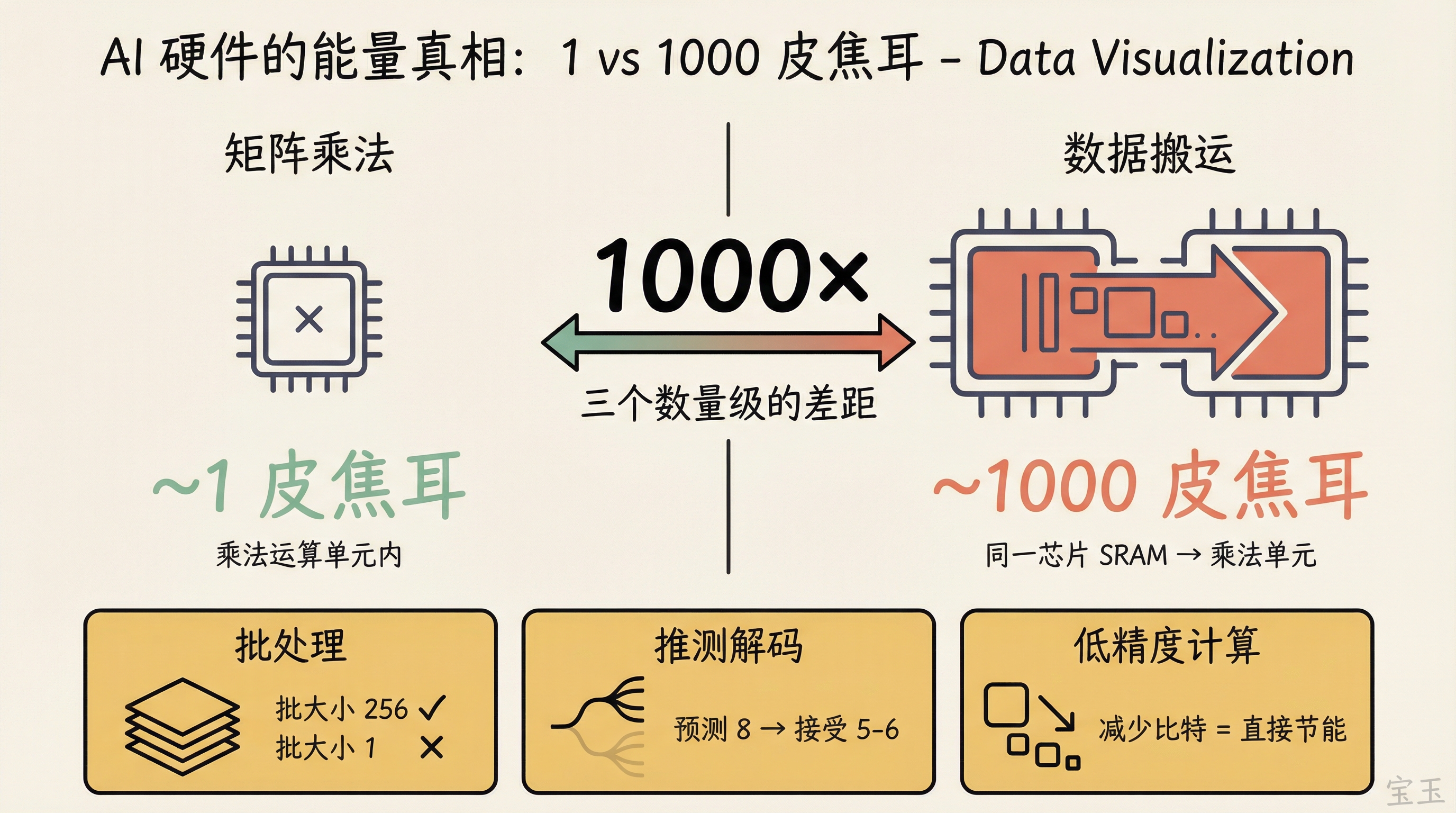
Jeff 说,AI 时代你真正需要关注的是能量。
核心数字是这样的:在矩阵乘法单元里做一次乘法运算,大约花不到 1 皮焦耳。但从同一块芯片的 SRAM(不是跨芯片,是同一块芯片的另一端)搬一个数据过来,大约 1000 皮焦耳。差了整整三个数量级。
【注:皮焦耳(picojoule)= 10⁻¹² 焦耳。作为对比,人脑每次突触传递消耗约 1-10 飞焦耳(10⁻¹⁵ 焦耳),比数字芯片低 3 个数量级。】
“这就是为什么加速器需要批处理。如果你把一个模型参数从 SRAM 搬到乘法单元,花了 1000 皮焦耳,你最好让这个参数被用很多很多次。批大小 256 还行,批大小 1 真的不行。”
理想情况下你想用批大小 1,因为延迟最好。但能量成本和计算效率不允许。Swyx 说从没听过从能量角度分析批处理的逻辑。Jeff 说“这就是大家做批处理的原因”。
沿着这个思路,Jeff 提到了几个正在探索的方向:推测解码(speculative decoding),预测 8 个 token 接受其中 5-6 个,相当于把有效批大小提升了 5-6 倍;低精度计算,能量消耗是按比特算的,减少比特数是最直接的节能方式;以及扩散模型和非自回归解码,不需要逐 token 生成,从根本上改变计算模式。
TPU 芯片设计:预测 2-6 年后的 ML 需求
Alessio 问:硬件和模型变化都这么快,做硬件定制值得吗?
Jeff 说,Google 的优势在于 ML 研究者和 TPU 硬件团队之间的紧密协作。芯片设计的时间跨度很长:从开始设计到进入数据中心需要 2 年,然后要服役 3-5 年。也就是说,你需要预测 2-6 年后的 ML 计算需求。
“在一个变化极快的领域里,你在试图预测 2-6 年后的需求。”
有两种策略。对于低成本的推测性特性,Jeff 倾向于“赌一把”:花一点芯片面积放进去,押对了可能带来 10 倍加速,押错了损失也不大。对于重大变更,则需要大量 ML 实验来确认方向。
Alessio 追问:有没有反过来的情况,芯片设计已定,模型架构只能去适应?Jeff 承认了,模型架构确实会被调整以适配即将投产的硬件。这是双向的。有时甚至会用未来硬件才支持的低精度来训练模型,即使当前一代硬件还做不到。
下一个大问题:怎么让 RL 在非可验证领域工作
Swyx 问 Jeff Dean 还有什么有趣的开放研究方向。
Jeff 认为最关键的开放问题是:如何让强化学习(RL)在非可验证领域工作。目前数学和编码的进步很大程度归功于 RL,因为这些领域的答案可以被验证——数学证明对不对、代码能不能跑通。如果能把 RL 扩展到不那么容易验证的领域,模型的能力将大幅提升。
Jeff 认为一种有效方法是用模型评估模型:让另一个模型判断第一个模型检索的内容是否相关,或者用同一个模型不同提示来做“评审者”。
他用一个对比说明进步有多快:
“两年前我们还在 GSM8K 上挣扎——‘Fred 有两只兔子,又买了三只,一共几只?’这和现在模型能做的数学完全不在一个层次上。”
另一个他关注的方向是:如何让模型可靠地完成更长更复杂的任务,包含大量子任务,可能需要一个模型调用其他模型作为工具。
【注:GSM8K 是一个小学数学应用题 benchmark,2022-2023 年间曾是衡量大模型推理能力的重要指标。RL 在可验证领域的成功(即 RLVR,Reinforcement Learning with Verifiable Rewards)是 2024-2025 年推理能力飞跃的核心技术。】
从 AlphaProof 到 Gemini:统一模型取代专用系统
Swyx 指出一个让他“至今没缓过来”的事实:2024 年 Google 用 AlphaProof + AlphaGeometry 两套专用系统拿了 IMO 银牌,需要先把数学题翻译成 Lean 形式语言。2025 年直接用一个接近生产版本的 Gemini 模型(带 Deep Think 模式),以纯自然语言解题就拿了金牌。
【注:Gemini Deep Think 在 IMO 2025 中解出 6 道题中的 5 道,获得 35 分(满分 42),达到金牌线。630 名人类选手中只有 67 人获得金牌。】
Jeff Dean 说这对他来说完全合理。人类操纵符号,但大脑里可能并没有符号表征。我们的大脑更像是一种分布式神经网络,大量神经元和激活模式在我们看到某些东西时触发。把完全独立的离散符号系统和神经网络分开做,从一开始就不太对。
他将此与 2013-2016 年的 ML 历史做类比:那时每个问题都要训一个专门的模型(街道标志识别、语音识别),现在进入了统一模型做所有事的时代。
参数空间该存知识还是推理能力?
Swyx 提出了模型容量的问题:小模型的参数空间有限,记住冷僻事实不如把空间留给推理能力。
Jeff 同意。让模型用宝贵的参数空间记住可以查到的冷僻事实,不是最佳利用方式。模型最应该擅长的是"在能检索信息的前提下进行推理“。但模型也不能完全脱离世界知识,比如知道金门大桥有多长是有用的,因为它提供了”桥梁大概多长"的一般性感觉。只是不需要知道世界上每座小桥的长度。
关于个人化 Gemini,Jeff 明确说不会把 Gemini 训练在你的邮件上,而是让它用检索作为工具,在多轮检索和推理之间交互。
那垂直模型还有价值吗?Jeff 的态度务实:有,但要从一个好的基础模型出发,用该领域的更多数据进一步训练。纯粹从头训练专用模型的时代已经过去了。不过数据混合有权衡:你想加入 200 种语言的数据?那就要挤占其他能力的空间,可能 Perl 编程能力就差一点,或者多模态推理就弱一点。
他还提出了一个更远的愿景:模块化的"可安装知识"(installable knowledge)。
“最好能有一种能力,让那 200 种语言加上很棒的机器人模块加上很棒的医疗模块,全部能编织在一起协同工作,在不同场景下按需调用。”
有些可安装知识可以通过检索实现,但有些可能需要在千亿级 token 的领域数据上训练。
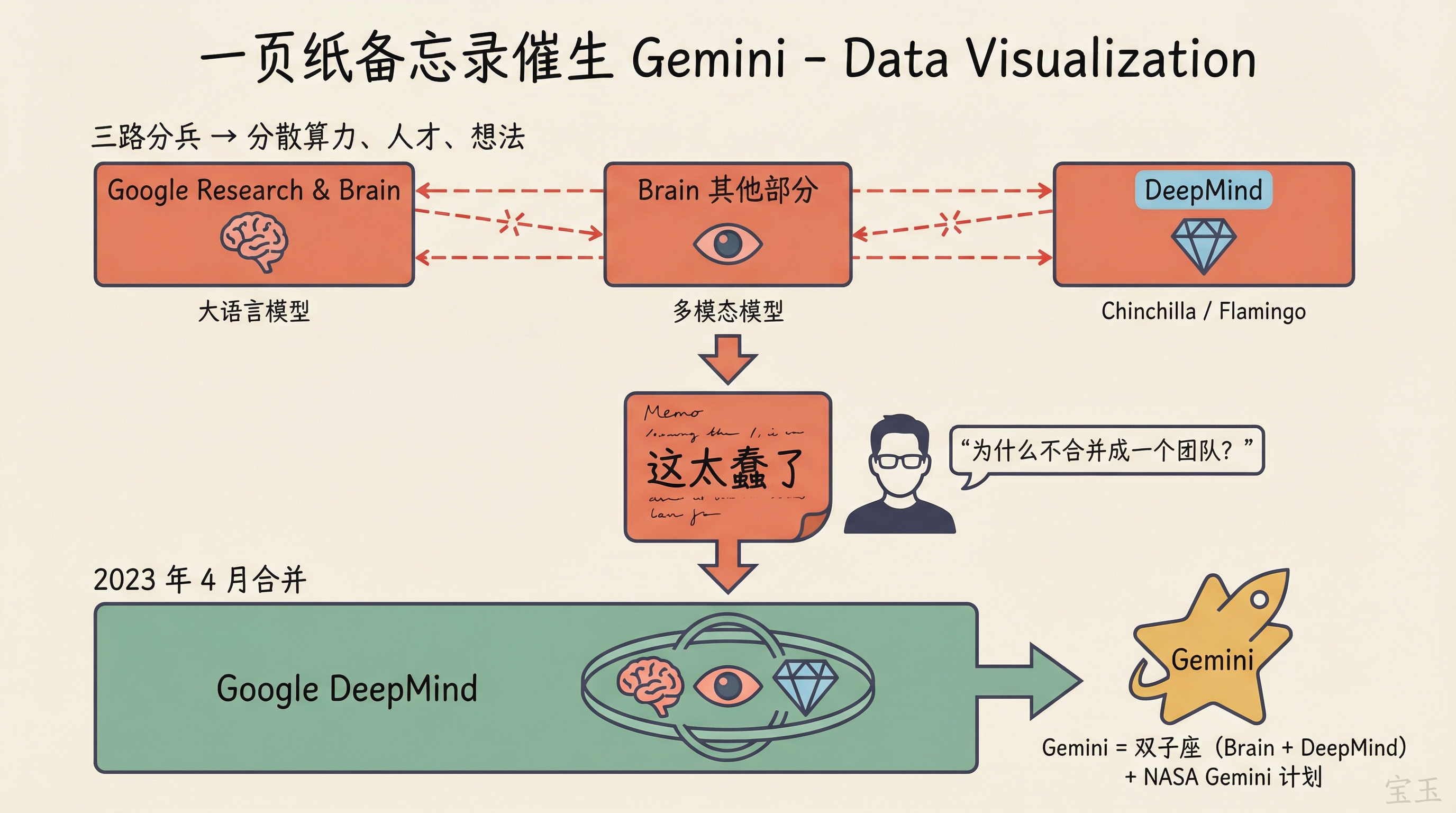
一页纸备忘录:Gemini 诞生的真实故事
Swyx 引用了前 Google 员工 David Luan 的观点:Google 在大语言模型上投入不够,是因为 Google Brain 内部的“计算配额市场”导致资源分散。OpenAI 敢把全部筹码压在一件事上,Google 更民主化,每个人都有配额。
【注:David Luan 曾任 OpenAI 工程副总裁,后在 Google Brain 任职,之后创立 Adept AI。】
Jeff Dean 说:
“我某种程度上同意这个说法。”
他部分认同了这个批评,然后讲述了自己推动改变的过程。当时的情况是:Google Research 和 Brain 团队在做大语言模型,Brain 的其他部分在做多模态模型,合并前的 DeepMind 在做 Chinchilla 和 Flamingo。三路分兵,不光分散了算力,还分散了最好的人才和最好的想法。
【注:Chinchilla 是 DeepMind 2022 年的大语言模型,以其提出的最优训练数据量比例(Chinchilla Scaling Law)著称。Flamingo 是 DeepMind 的多模态视觉语言模型。】
他写了一份一页纸的备忘录,核心观点是:
“这太蠢了。为什么不合并成一个团队,训练一个从一开始就是多模态的、擅长所有事情的统一模型?”
这份备忘录成功了。它推动了 Google Brain 和 DeepMind 的合并,也催生了 Gemini 项目。
Swyx 问,Gemini 这个名字是你起的吗?Jeff 说是的。Brain 和 DeepMind 就像双子(twins,Gemini 在拉丁语里是“双胞胎”的意思)走到一起。同时也有 NASA Gemini 计划的含义:那是通往 Apollo 登月的重要一步。
【注:2023 年 4 月,Google 将 Google Brain 和 DeepMind 合并为 Google DeepMind,由 Demis Hassabis 担任 CEO,Jeff Dean 担任首席科学家。】
微型厨房里的 Google Brain
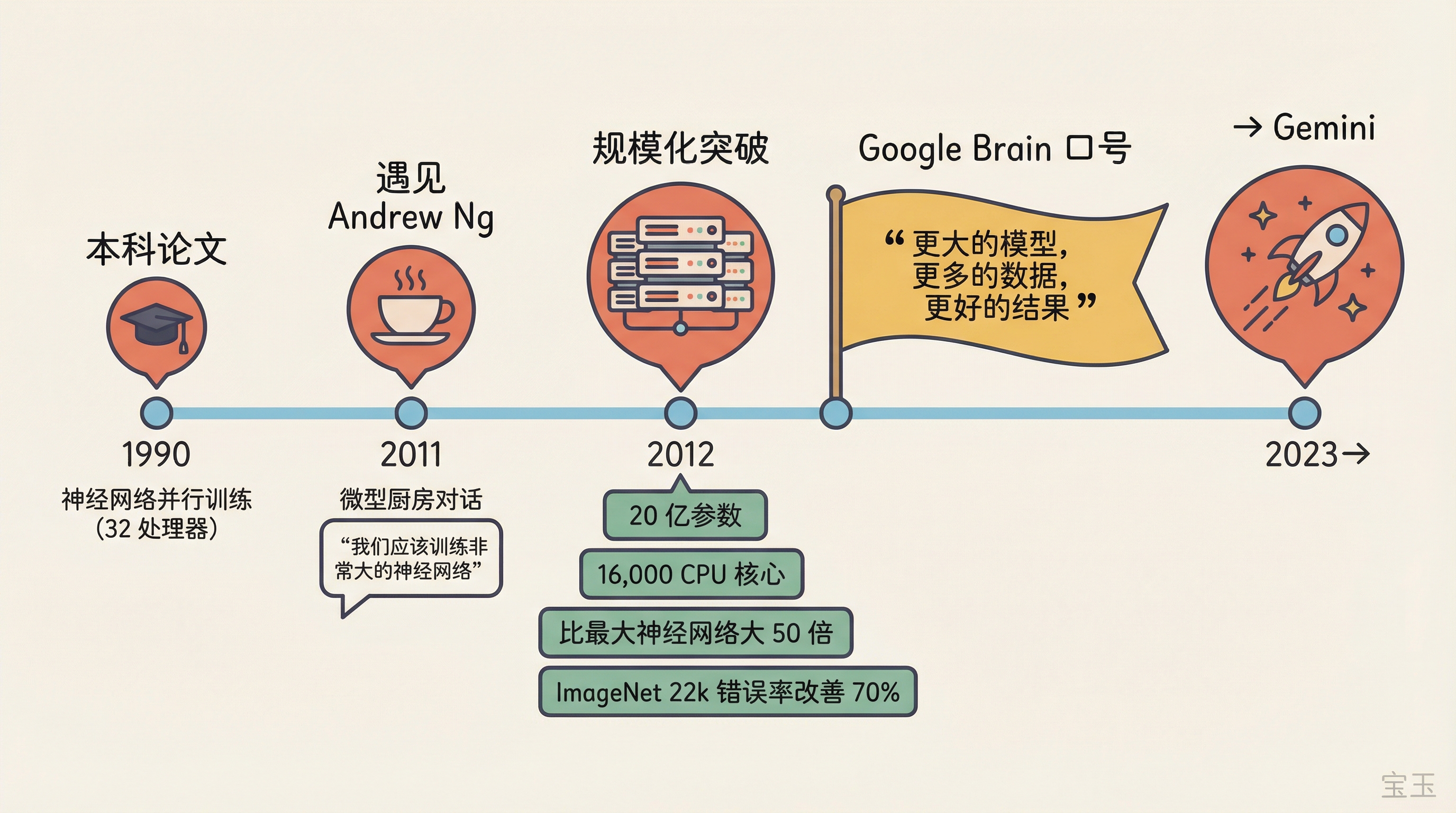
Jeff 还回忆了 Google Brain 的起源故事。
2011 年底,他在 Google 的微型厨房(micro kitchen,Google 办公室里散布的小休息区)遇到了 Andrew Ng。Ng 刚以每周一天顾问的身份加入 Google,还不确定要做什么。他说他 Stanford 的学生开始在用神经网络做语音识别方面取得不错的结果。
Jeff 一听就来了兴趣:
“我喜欢神经网络。我想到了 1990 年的本科论文。我当时就说:我们应该训练非常、非常大的神经网络。”
当时 Google 的数据中心里没有 GPU,只有大量 CPU。但 Jeff 觉得可以构建一个软件系统,用模型并行和数据并行把训练分布到大量计算机上。他复用了自己 1990 年在明尼苏达大学本科论文中用系里 32 处理器并行计算机做的一些思路。
最终他们训练了一个 20 亿参数的视觉模型,在 16,000 个 CPU 核心上跑了数周,比此前最大的神经网络大 50 倍。在 ImageNet 22k(22,000 个类别)上取得了 70% 的相对错误率改善。
这让他们确信了规模化的方向。虽然当时没有写正式的 scaling analysis,但 Google Brain 有一句口号用了六七年:
“更大的模型,更多的数据,更好的结果。”
每次试这个方法,在语音、语言、视觉上都看到了更好的结果。
AI 编程的未来:规格说明的复兴与 50 个实习生
Alessio 问 Jeff Dean 怎么用 AI 写代码。他和 Sanjay Ghemawat 结对编程的故事是计算机科学史上的经典,那他怎么看人与 AI 编程工具的协作?
【注:《纽约客》2018 年刊登了 James Somers 撰写的长文“The Friendship That Made Google Huge”,讲述二人长达数十年的合作。】
Jeff 说工具进步很大,可以委托越来越复杂的任务。他强调了一个关键点:你和编程模型的交互风格本身就在塑造输出。你可以让它“写一组好的测试”,也可以让它“帮我头脑风暴性能优化方向”,不同的提问方式会得到不同质量的结果。有些任务适合频繁互动(确保方向正确),有些适合放手(“请去写这个东西,完成了再来找我”)。
他用了一个生动的比喻:如果你有 50 个实习生怎么管理?你不会直接管理 50 个人,你会让他们分成小团队,然后你跟 5 个团队交互。
学校一直在教“写软件规格说明很重要”,但没人真正当回事,大家都觉得“我不需要写 spec,直接写代码”。但在 AI 编程时代,你给 Agent 的指令就是 spec。
“如果你要让 Agent 帮你写软件,你最好对怎么描述需求极其小心,因为你的描述质量直接决定输出质量。如果你没提到某个重要的边界情况,或者没说你特别在意某部分的性能,模型可能就不会做。”
清晰表达需求会越来越重要,无论你是软件工程师还是做其他工作。
Swyx 开玩笑说:“好的 prompting 跟高级别的管理者沟通没什么区别。就像写内部备忘录一样。”
两个预测:个性化模型与 10,000 token/秒
最后 Swyx 请 Jeff Dean 做预测。他给了两个。
第一,个性化模型会远超通用模型的实用性。一个知道你是谁、能在你授权下检索你所有个人数据的模型,比一个没有这些上下文的通用模型有用得多。“它能注意到你看过的每封邮件、每张照片、每个视频。”
第二,专用硬件会实现远低于现在的延迟和更强的能力。
Swyx 追问了延迟的具体量级。现在大概 100 token/秒,能到多少?Jeff 说 10,000 token/秒是有意义的目标。
Swyx 说 10,000 token/秒你已经不是在“读”代码了,代码生成太快了根本来不及读。Jeff 纠正了这个理解:
“最终可能不是 10,000 token 的代码。可能是 1,000 token 的代码,加上背后 9,000 token 的推理过程。”
更多 token 意味着可以做更多的并行推演、生成更多候选并验证正确性、用更充分的链式推理来保证质量。“如果我有更多时间,我会写一封更短的信”,更多的推理 token 不是为了产出更多代码,而是为了产出更好、更精炼的代码。
Swyx 反驳说,就算硬件延迟降低 20 倍,到时候也会有更强的模型需要更长的计算时间。Jeff 说:帕累托曲线总是在往前爬。

几个核心线索贯穿这次访谈。AI 的前沿能力和部署效率是乘法关系,不是竞争关系。从 Google 搜索的分层检索到“关注整个互联网”,从 1990 年的本科论文到万亿参数模型,扩展的信念一以贯之,但不是盲目扩展,硬件、架构、数据、算法的进步必须彼此相乘。而能量效率可能是 AI 基础设施领域最被低估的约束。
Google 的个性化 Gemini 何时真正落地?“可安装知识”的模块化架构是概念还是已经在路上?RL 能否突破可验证领域的边界?这些问题的答案,可能比下一个 benchmark 分数更值得关注。