快不等于好:Anthropic 和 OpenAI 的快速模式藏着什么
宝玉
Anthropic 和 OpenAI 最近先后发布了各自的“快速模式”,都是给 AI 编程助手加速。但仔细看,两家走的是完全不同的技术路线,背后的产品哲学也很不一样。
两种快速模式,到底有什么区别
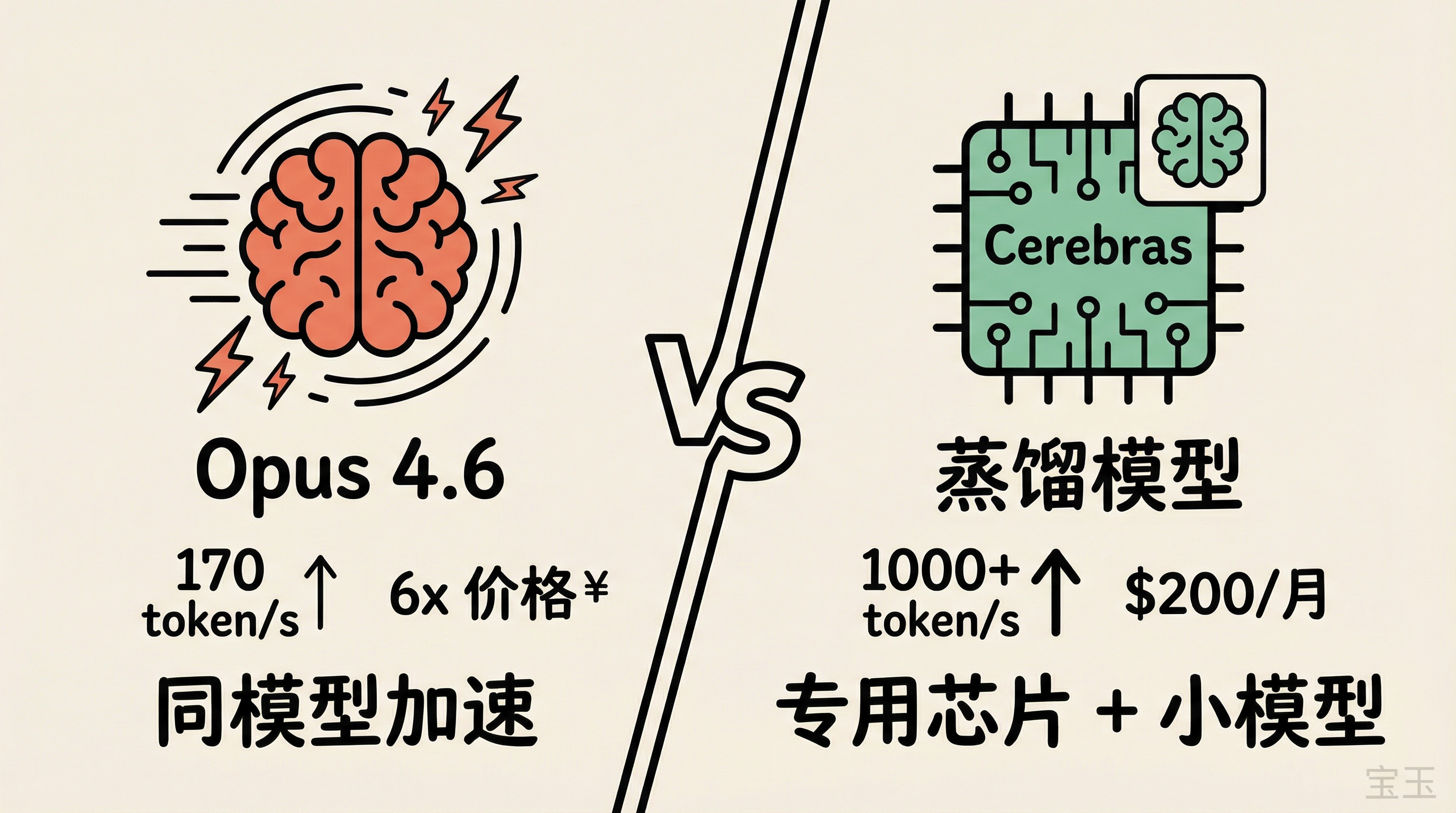
Anthropic 的 Fast Mode 在 2 月 8 日上线,面向 Claude Code 和 API 用户。开启后,Opus 4.6 的输出速度从约 65 token/秒提升到约 170 token/秒,快了 2.5 倍。代价是价格翻 6 倍:输入从 5 美元/百万 token 涨到 30 美元,输出从 25 美元涨到 150 美元。
特别提醒一下用 Claude Code 的朋友,Fast Mode 的费用走 extra usage 通道,不从订阅配额里扣。也就是说就算你是 $200 一月的订阅,Fast Mode 产生的费用都要你自己掏钱,慎重!不过用 GitHub Copilot 的话,里面的 Token 计费是普通模型 x6 倍,算在包月里面的,相对还可以接受。
Fast Mode 不是另一个模型。 Anthropic 反复强调,快速模式跑的是完全相同的 Opus 4.6,智能水平和输出质量不变。你付的是“加急费”,买的是同一个模型的更快服务。
OpenAI 则在 2 月 12 日发布了 GPT-5.3-Codex-Spark,是 GPT-5.3-Codex 的一个“轻量版”蒸馏(Knowledge Distillation)模型,专门为实时编程设计。速度达到 1000+ token/秒,是原版 Codex 的 15 倍。目前只对 ChatGPT Pro 用户开放。
硬件也不一样。Spark 跑在 Cerebras 的第三代晶圆级引擎(Wafer Scale Engine 3)上,这是 OpenAI 今年 1 月宣布的超过 100 亿美元合作的首个成果,也是 OpenAI 第一次在生产环境中使用非 Nvidia 芯片。
但能力有差距。在 Terminal-Bench 2.0(衡量 agent 终端操作能力的基准测试)上,完整版 Codex 得分 77.3%,Spark 是 58.4%。有人做了个直观测试:让两个模型各写一个贪吃蛇游戏,Codex 5.3 花了 6 分钟,每个边界情况都处理到位;Spark 50 秒就跑出来了,游戏能玩,但细节上有瑕疵。
在 SWE-Bench Pro(更接近真实软件工程任务的测试)上,差距小一些:Spark 大约 2-3 分钟完成的任务,完整版 Codex 需要 15-17 分钟,准确率接近。
目前 Spark 只对 ChatGPT Pro 用户开放($200/月),上下文窗口 128K,不支持图片输入,API 访问限于少量合作伙伴。
一句话总结区别:Anthropic 是同一个模型跑得更快,OpenAI 是换了一个更小的模型跑在专用芯片上。
为什么能快
Anthropic 没有公开 Fast Mode 的技术细节。技术博主 Sean Goedecke 推测是降低了推理时的批处理大小(batch size),但这个说法在 Hacker News(以下简称 HN)上被多位从业者质疑。现代推理系统早就用上了连续批处理(continuous batching),“等批次凑满再出发”这种事基本不存在了。
HN 讨论中有几个更靠谱的猜测:
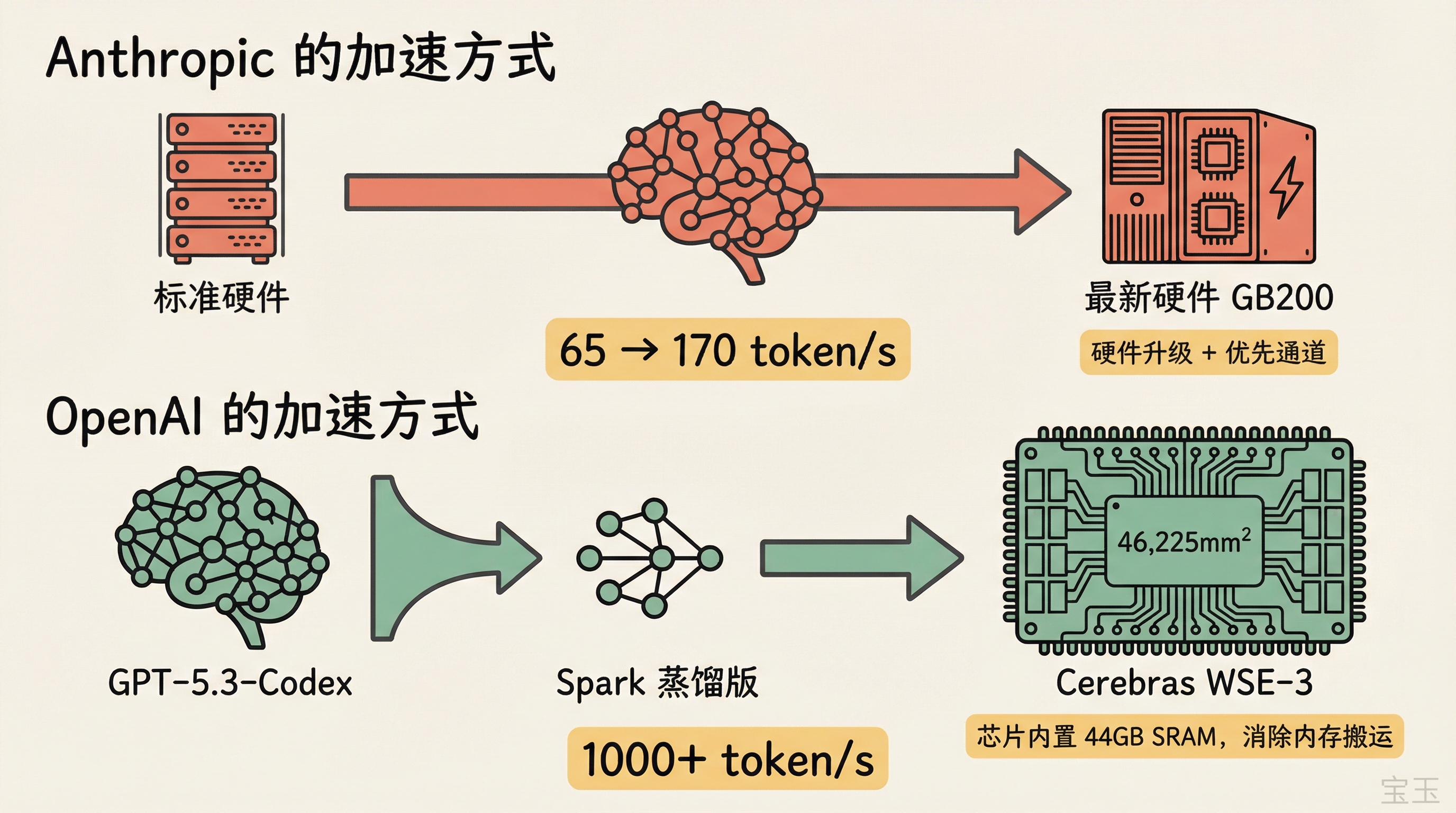
- 路由到最新硬件:把 Fast Mode 请求全部路由到最新一代硬件上(比如 GB200,显存带宽是 H100 的 2.4 倍),硬件代差本身就能带来明显提速
- 并行蒸馏和精炼:来自用户 ankit219 的推测,Anthropic 可能先并行跑多条推理路径,再快速蒸馏合并出答案。这能解释一个反常识的现象——有用户反馈 Fast Mode 在某些难题上表现反而比标准模式更好
OpenAI 这边公开得多。Spark 跑在 Cerebras 的 WSE-3 上,一块面积 46,225 mm² 的晶圆级芯片,大约是英伟达 H100 的 57 倍大。
这块芯片的核心优势是片上集成了 44GB 的 SRAM(静态随机存取内存),访问速度比 GPU 常用的 HBM(高带宽内存)快大约两个数量级。GPU 推理时大量时间花在从外部内存搬运模型权重上,Cerebras 把模型直接放在芯片内部,消除了这个搬运开销。
44GB 的 SRAM 显然装不下完整的 GPT-5.3-Codex,所以 OpenAI 训练了一个更小的蒸馏版本。具体多大不清楚,但 Cerebras 芯片可以多片串联,所以 Spark 的参数量可能比"44GB 能装下的"要大不少。
速度和准确率,哪个更重要
这是两种 Fast Mode 背后真正的产品分歧。
Anthropic 赌的是:开发者最在意的是模型不犯错。 所以给你同一个最聪明的模型,只是让它跑快一点。你多花的钱买的是“不降智”。
OpenAI 赌的是:开发者需要实时交互的体验。 1000 token/秒意味着代码生成速度比大多数人的阅读速度还快,这已经跨过了从“批处理工具”到“实时协作者”的门槛。
哪个更对?取决于使用场景。
对于坐在终端前和 AI 来回对话的交互式开发,速度差异是实实在在的。Opus 4.6 标准模式下一个复杂重构可能要等 30 秒,快速模式下 12 秒。这个差距足以影响你能不能保持“心流”状态。
但对于 AI agent 自主完成多步骤任务的场景,速度可能没有看起来那么重要。一个 HN 评论者算了一笔账:如果 agent 每步决策有 80% 准确率,串联 10 步后端到端成功率只剩约 10%。agent 任务中大部分时间花在工具调用上(API 请求、文件读写、等外部服务),模型推理速度快 6 倍,对整体耗时的改善可能远没有 6 倍。
速度对实时语音 AI 的意义可能更大。 人对对话中超过 800ms 的停顿就会觉得不自然。语音 agent 的流水线(语音识别 → LLM 推理 → 语音合成)中,留给 LLM 的窗口只有约 400-500ms。常规速度下这个窗口只够生成约 35 个 token,勉强一句话。1000+ token/秒的速度能让这个窗口生成 400+ 个 token,对语音交互的设计空间是质的改变。OpenAI 有自己的语音产品线,这可能是他们投入 Cerebras 合作的一个重要考量。
速度优势还能转化为准确率。与其用一条推理路径快速得到一个不太靠谱的答案,不如同时跑多条候选路径,选最优的那个。速度够快的话,跑 3 条路径选最好的,总时间可能还比标准模型跑 1 条路径短,准确率反而更高。

普通用户怎么选
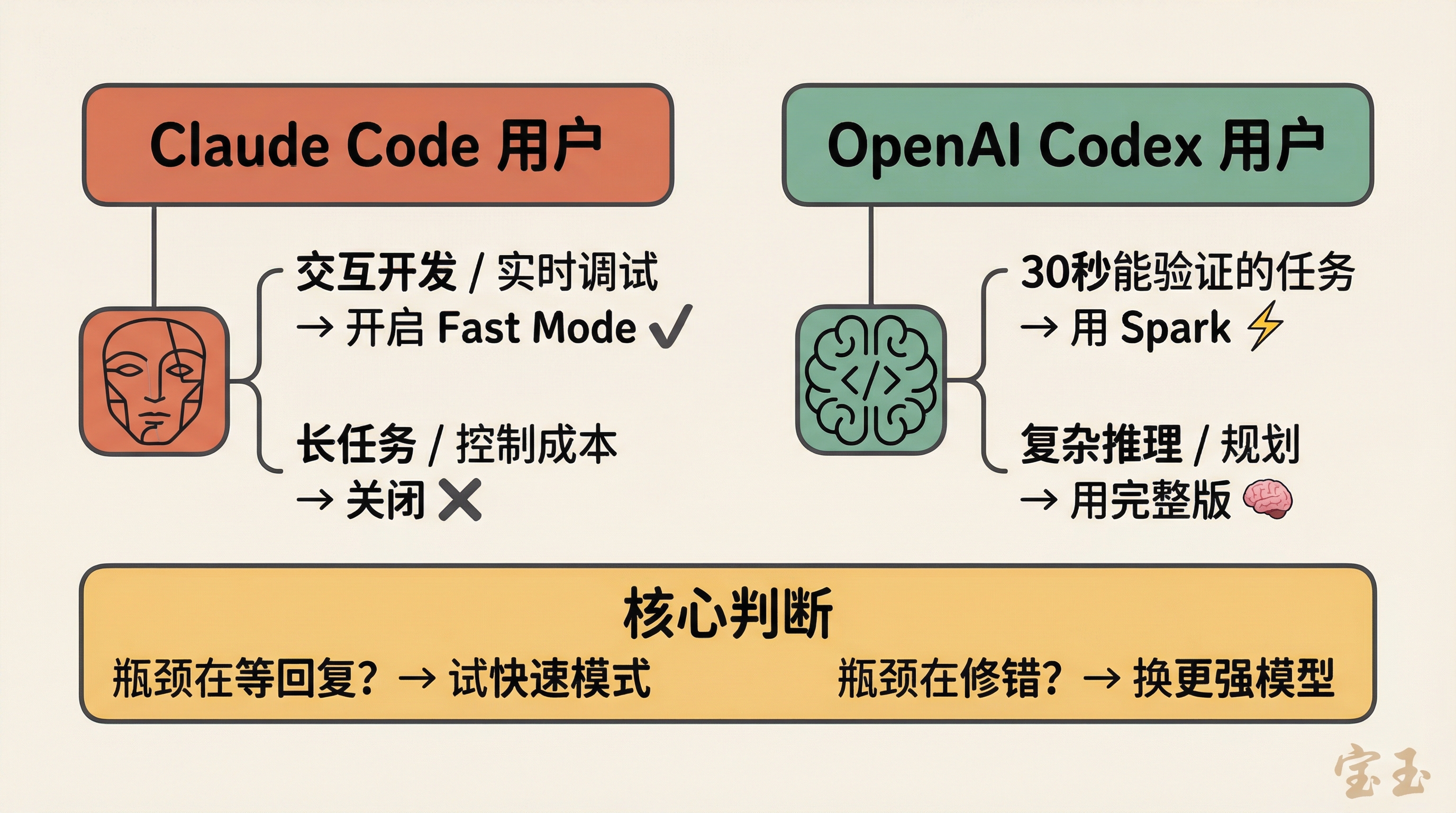
如果你是 Claude Code 用户,快速模式的使用场景很明确:交互式开发、实时调试、需要快速迭代的时候打开,跑长任务或对成本敏感时关掉。
如果你是 OpenAI Codex 用户,Spark 的定位更微妙。社区已经摸索出一个比较合理的使用模式:让完整版 Codex 负责规划和复杂推理,Spark 负责小改动、生成测试、格式调整这类可以快速验证的任务。有人总结了一个判断标准:这个任务的结果能在 30 秒内验证吗?能的话用 Spark,不能就用完整版。
OpenAI 也提到未来可能推出“混合模式”,根据任务复杂度自动路由到 Spark 或完整版 Codex,但目前还需要手动切换。
价格方面,Anthropic 的快速模式是明码标价的贵(6 倍),但你清楚自己买的是什么。Spark 目前只对 ChatGPT Pro 用户开放,API 定价还没有最终确定。
务实建议:别因为"快"就默认开启。 先想清楚你的瓶颈在哪。如果大部分时间花在等模型回复上,快速模式值得试。如果大部分时间花在修复模型犯的错上,你需要的不是速度,而是更好的 Prompt 或者换个更强的模型。
最后
两家公司几乎同时推出快速模式,反映的是行业共识的转变:模型智力的军备竞赛之外,推理速度正在成为新的竞争维度。
一个是精算师思维,一个是探险家思维。Anthropic 卖的是确定性(同模型、同质量、就是更快),OpenAI 卖的是可能性(新芯片、新模型、速度质变)。
至于谁的路线更有前景,可能要看 Cerebras 的产能能不能跟上,以及 OpenAI 能不能在这些芯片上跑越来越大的模型。如果未来完整版 Codex-5.3 也能在 Cerebras 上跑到 1000 token/秒,那就是另一个故事了。
参考资料:
- Sean Goedecke 的分析博客:https://www.seangoedecke.com/fast-llm-inference/
- HN 讨论:https://news.ycombinator.com/item?id=47022329
- Anthropic Fast Mode 文档:https://platform.claude.com/docs/en/build-with-claude/fast-mode
- OpenAI Codex Spark 公告:https://openai.com/index/introducing-gpt-5-3-codex-spark/